
Redux and Doman‑Driven Development
This article was originally published at medium.com ⬈
Dan Abramov, the creator of Redux, says that he does not know what Domain-Driven Design is. Still, it is impressive how Redux resembles DDD. In this article, I explain what DDD, some key concepts, and how Redux implements its ideas. And understanding both, we can deliver even better implementations; two approaches from different worlds that collide and take advantage of the same design principles.
Alas, I don’t know DDD. Can you show code examples of either approach? Generally you want to treat state as a database.
— Dan Abramov (@dan_abramov) May 13, 2016
Domain-Driven Design
Domain-Driven Design is a software modeling technique designed to create robust microservices architectures as well as integrate multiple existing solutions.
Eric Evans initially presented it in 2003 in the book «Domain-Driven Design: Tackling Complexity in the Heart of Software.» Currently, DDD has many more books, more examples, and it has proved to be effective scaling and maintaining high-grade performance in large systems. If you have listened about Event-Sourcing or CQRS, then you have crossed your paths with DDD.
We can split DDD into two areas: strategy and tactics. The strategy introduces the Ubiquitous Language and Bounded Context. It creates a common language between the developers and the business, but this language goes beyond meetings: all documentation, stories, and even code shares that language. Every declared variable, function, class, or package name matches the Ubiquitous Language.
The tactics are more about how to implement the system. The main target is to enable a system scale across many microservices in many locations. Abstractions used are queries, commands, domain events, and aggregates. The application directs queries and commands towards the aggregates, aggregates do all computations, and domain events maintain eventual consistency in the whole system.
The relevant concepts of the tactics are:
Queries: Any question that you can do to the system. It does not change its state or any data. It is something that you ask for, and it responds with information. There are no side-effects. Example of query: list the available posts.

Commands: are requests for a mutation. They may work, or they may fail. The system executes them and returns the result. Some variants, like CQS, do not allow commands to return a value. Example of command: add a new post.

Domain Events: are the key; they represent the effect of a cause; They are facts, something that had happened. Events do not fail and cannot be canceled. Any component in the application can listen for any event; when any of them receives an event, they update itself and generate new events as a consequence. Domain events enable eventual consistency. Examples of domain events are: a new post is added, or it is five o’clock.

Aggregates: is the main pattern of the DDD. It represents small pieces of models (ideally just one entity and few object values). Models are reasonably isolated. Aggregates communicate with each other through queries, commands, and domain events. They consume domain events to keep their states consistent, and at the same time, they generate new domain events for each mutation. Example of aggregate: post.

Unfortunately, many people confuse Commands and Domain Events. Both are verbs, and both may imply a mutation in the state, but they are different. Commands are intentions, and Domain Events are facts. That is why commands may fail, but domain events cannot. Commands are something that we want to happen, and Domain Events are something that had happened.
If you want to learn more about DDD, I strongly recommend reading the book of Vernon Vaughn «Domain-Driven Design Distilled» (2016). This book quickly introduces all concepts and gives a comprehensive view of how to start doing DDD.
Redux
Redux is shockingly related to Domain-Driven Design. Although it does not share the same terminology, the ideas are present. Redux is almost an implementation of the tactics of DDD in a functional paradigm.
Let’s compare the previous concepts with Redux:
Queries: they are selectors. Selectors obtain a piece of information from the state.
Commands: they are actions. When we dispatch an action, we submit a new command. Redux does not provide a result because it implements a pure CQS.
Events: they are actions, too. But, ¿when an action becomes a fact? Once it is reduced. After reducing an action, it becomes a fact, something that does not change.
Aggregate: the aggregate is who computes all changes; this is the reducer.
Unfortunately, Redux vocabulary does not make easy distinguish between commands and domain events. DDD uses infinitive verbs to denote commands; and the past participle for events. Still, it is common to see redux action types like command “FETCH_POST” or event “FETCH_POST_SUCCESSFUL.”
DDD Patterns on Redux
Two patterns have made DDD popular: Event Sourcing and CQRS. Both have born from the necessity to improve scalability and performance, and both techniques are usually applied in Redux.
The first is Event Sourcing. The objective of DDD for event sourcing is to increase the throughput of writes in a database. Instead of saving each change in the database, it only stores the domain events emitted by each aggregate and, when it is possible, a snapshot of the aggregate. The reasoning is simple: you can reconstruct the state of any aggregate by replaying its events.
For example, you can reconstruct all posts by replaying PostAdded events.
Are you familiar with this concept in Redux? Almost sure, yes. In Redux, this is called Time Traveling, and probably you have been using it a lot while debugging in the developer tools.
This pattern is great; it does not only allows us to fix bugs more quickly, or speed writes on servers, but it helps to make the application safer. Data loss? No problem, replay the events, and you can reconstruct the state. Data corruption due to a bug? Solve the bug, replay events, and obtain a pristine state. Are you helping other users? Just replay their events to know which is their state.
The second is CQRS. The objective of DDD for CQRS is to create models that combine the data from multiple aggregates. Instead of performing numerous slow queries, make one quick fast query on one single model. If Event Sourcing tackles slow updates, it addresses slow queries. The idea is that a unique model would consume multiple events and would compute a derived state, consistently. Then, consume that new model. For example, we can create a model to count posts. It receives PostAdded events and increments the count with each.
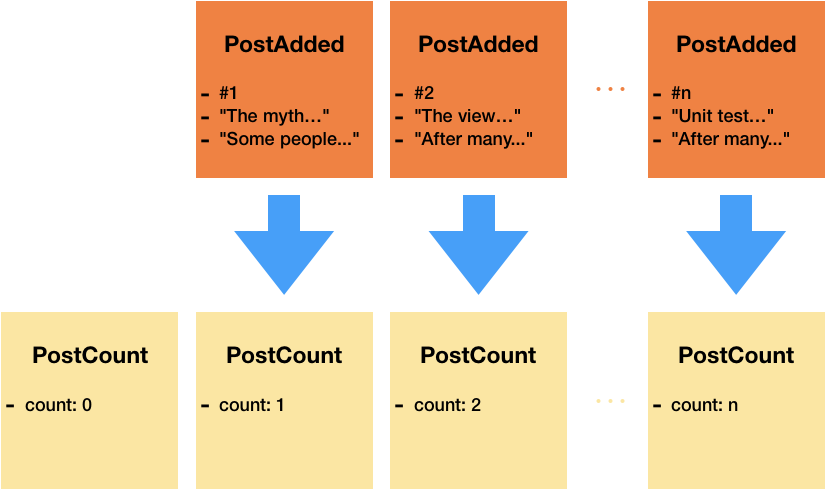
The equivalent in Redux is multiple reducers updating with the same action in different places. Although we have selectors with memoization, some times, we prefer to keep computed derived data to boost performance. For example, when we have an object with entities indexed by keys, but we have an array with the keys. It speeds list queries.
function reducePosts(state, action) {
switch (action.type) {
case ADD_POST:
return { ...state, [action.post.id]: action.post };
...
}
}
function reducePostList(state, action) {
switch (action.type) {
case ADD_POST:
return [...state, action.post.id];
...
}
}
function getPostList(state) {
// instead of Object.keys(state.post)
return state.postList;
}DDD dependency decoupling. Although it is not a pattern, DDD nicely decouples aggregates between them. It is one of the main strengths of DDD, beyond the scalability in performance. The concept of aggregate and how it interacts with others it gives a high degree of maintainability and better implementations. It is this precise property that prevents the creation of the harmful Big Ball of Mud.
Let’s see an example: we have a company that sells products and uses marketing campaigns to make offers. Existing units in shops are labeled initially by their corresponding product selling price, but when the campaign starts, it relabels units with the advertised price.
Without DDD we have a code like the following:

// Without DDD
class Campaign {
...
startCampaign() {
product.relabelUnits(advertisedPrice);
}
}
class Product {
...
relabelUnits(price) {
units.forEach(unit => unit.relabelPrice(price);
}
}
class Unit {
...
relabelPrice(price) {
labeledPrice = price;
}
}If we apply DDD we can relay on domain events to update other aggregates:
// With DDD
class Campaign {
...
startCampaign() {
emit(new CampaignStarted(..., productId, advertisedPrice));
}
}
class Unit {
...
onCampaignStarted(event) {
labeledPrice = event.advertisedPrice;
}
}Did you have noticed the difference? Now Product has disappeared. The Product does not depend anymore from the Unit. We have reduced the coupling of the application, and we can plug and unplug the units from our application without changing any code.
Redux does the same decoupling. Each combined reducer is like one aggregate. When a reducer receives one action, it reduces it independently.
function reduceUnit(state, action) {
switch (action.type) {
case START_CAMPAIGN:
return { ...state, labeledPrice: action.advertisedPrice };
...
}
}Conclusion
Redux and DDD present many similarities, and both share many of the advantages. Although they are created from different abstractions and from different backgrounds, both benefit the same architectural principles.
The main difference is the domain events. This concept does not exist clearly in Redux. It has consequences, and it will probably be studied in further articles.